Your endpoint should be a functionnot a lifestyle
# inference in one file
from flexai import endpoint
@endpoint(
latency_target_ms=180,
budget_monthly_usd=5000,
scale=(0, 512),
gpu="best_for_workload",
region="closest"
)
def chat(req):
model = load("your-model")
return stream(model.generate(req.prompt))
# deploy
flexai deploy chatLooks simple because it should be.
Production visibility without guesswork
Understand what happened without digging through tools and logs.
Live usage metrics
Latency, tokens, GPU, region, cache. In one view.
Cost lens
What is expensive, what is waste, what to fix next.
AutoScaling
Scale Fractional or Full GPUs based on traffic.
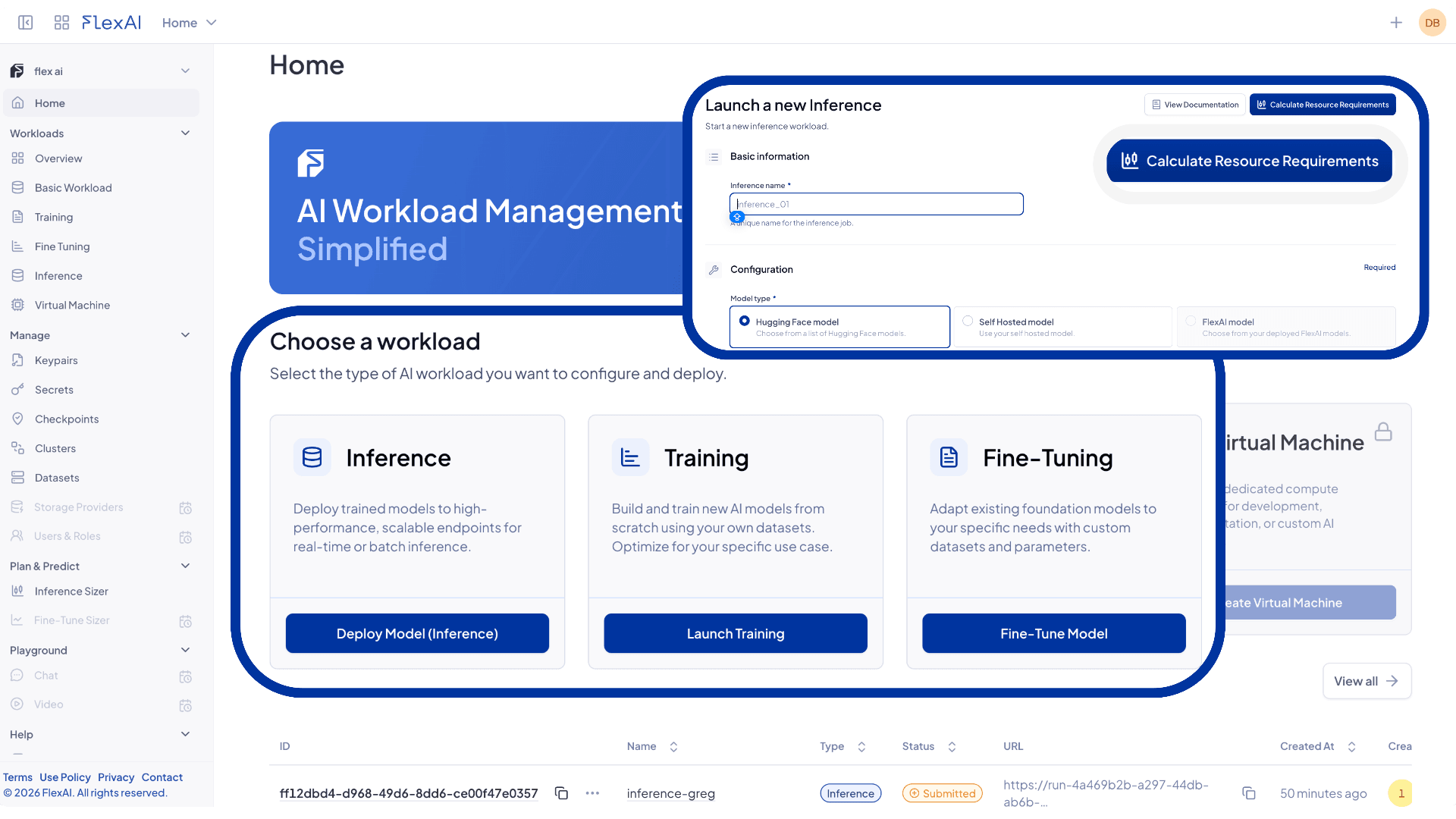
Ship inference like it isa feature, not a project
Built for teams shipping real inference to real users. Sizing a workload? Compare costs in the GPU savings calculator or see bare metal for dedicated capacity.
flexai deploy \
--workload inference \
--constraint latency=p95:180ms \
--constraint budget=$5000 \
--constraint scale=0..512 \
--constraint gpu=bestFAQ
The questions you will ask anyway
Do I have to pick a cloud⌄
No. You pick outcomes. FlexAI figures out placement.
Is this only for LLMs⌄
Any inference workload that needs predictable latency, throughput, or cost control.
What if my traffic is spiky⌄
That is the whole point. Scale up fast, then back down.
Can I start from a blueprint⌄
Yes. Treat it like a shortcut, not a tutorial.
Docs
Everything you need to deploy without reading a manifesto.